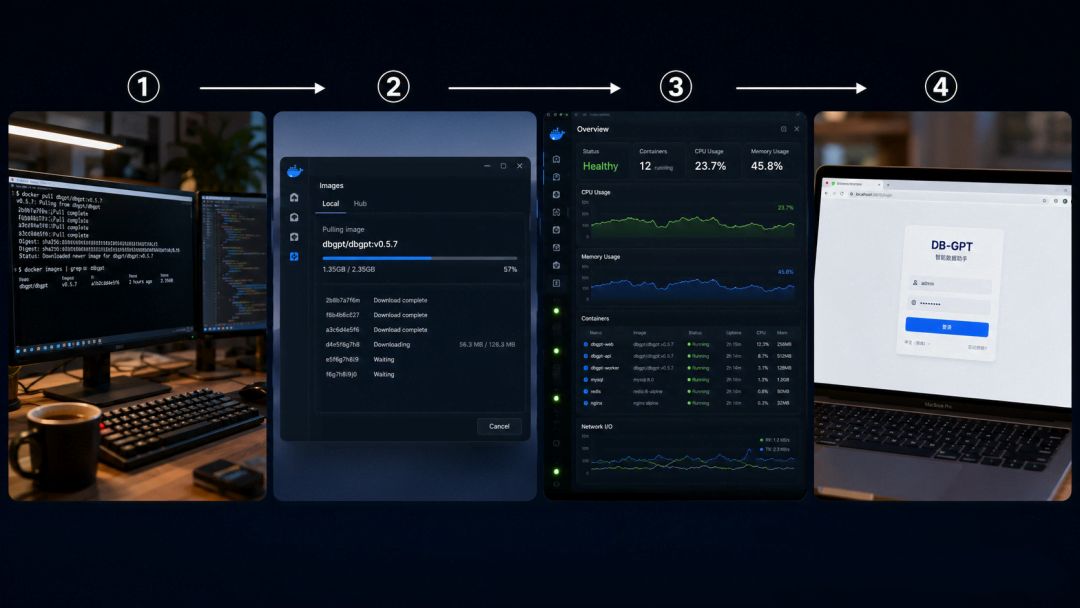
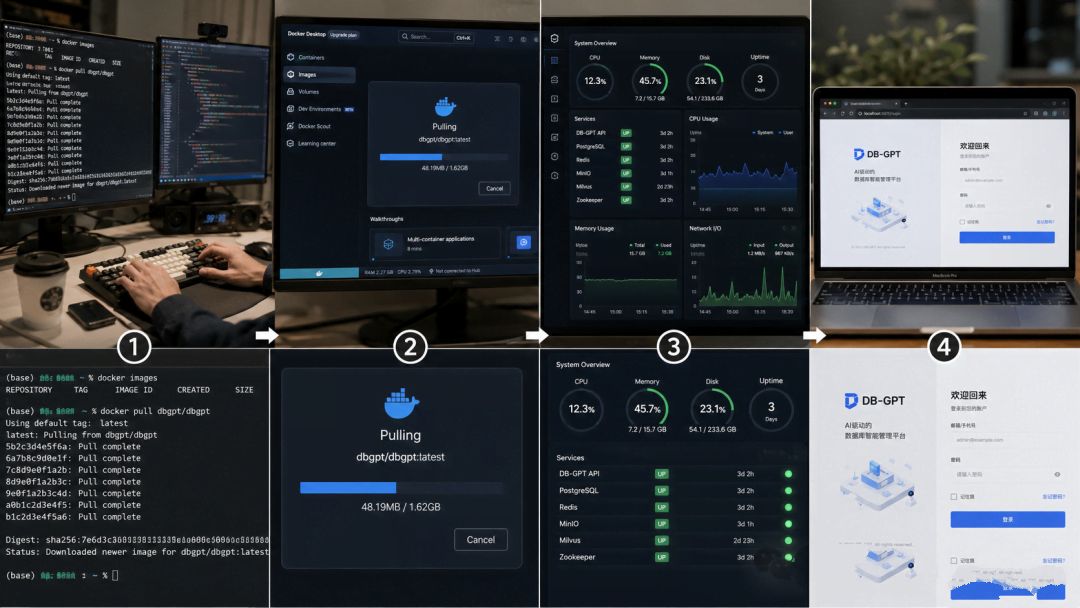
自然语言查数据 + 权限管控,完整落地方案
老板问:华南区本月的产能达成率是多少?
你需要:
• 打开ERP → 登录 → 找报表 → 筛选区域和时间 → 导出Excel → 计算达成率 → 发给老板
耗时:20分钟
如果老板能直接问AI,AI自动去ERP查,5秒返回答案呢?这件事2026年已经能落地了。
先说清楚:这套方案能解决什么问题
📊 | 场景1:老板随时查经营数据
"本月华南区产能达成率多少?""哪个供应商来料合格率最低?"——直接问,AI去数据库查,秒回。 |
🏢 | 场景2:销售总监查自己区域的数据
问"本月销售额"——AI只返回他管辖区域的数据,不会看到其他区域的数据。 |
🔒 | 场景3:财务查科目余额但看不到员工薪酬
财务能查科目,但查不了工资表——权限管控在查询执行前就拦截了。 |
核心架构一句话
用户问自然语言 → AI转换成SQL → 执行前做权限校验,动态注入过滤条件 → 返回结果 → AI用自然语言解读 |
第一部分:让AI直连ERP数据库(Text2SQL实操)
原理:Text2SQL是什么?
你问:"本月华南区销售额是多少"
AI自动生成SQL:
SELECT SUM(amount) FROM orders
WHERE region='华南' AND MONTH(create_time)=5 AND YEAR(create_time)=2026
执行SQL → 拿到结果 → AI用自然语言告诉你答案
整个流程不需要你写一行SQL。 |
方案选型:3种落地方式对比
方案 | 适合谁 | 技术难度 | 费用 |
DB-GPT(推荐) | 有技术能力
想私有部署 | ⭐⭐⭐ | 免费(需服务器) |
FastGPT + 插件 | 已用FastGPT
想快速扩展 | ⭐⭐ | 免费(需服务器) |
商用ChatBI产品 | 不想折腾
预算充足 | ⭐ | 500~3000元/月 |
下面以方案1(DB-GPT)为主,手把手实操。
准备条件
• 一台云服务器(最低配置:2核4GB,约30元/月)
• ERP数据库的连接信息(IP、端口、用户名、密码)
• 约1小时时间
⚠️ | 安全提醒:请用只读账号连接ERP数据库,不要给AI写权限,避免误操作。 |
Step 1:安装DB-GPT(10分钟)
DB-GPT是蚂蚁集团开源的AI原生数据应用开发框架,专门做Text2SQL场景。
1.1 登录云服务器,安装Docker:
curl -fsSL https://get.docker.com | bash -s docker
systemctl start docker
systemctl enable docker |
1.2 一键部署DB-GPT:
git clone https://github.com/eosphoros-ai/DB-GPT.git
cd DB-GPT
docker-compose up -d |
💡 | 提示:国内服务器拉取GitHub慢,可以用国内镜像,或者先把代码包下载到本地再上传。 |
1.3 访问验证:
等待约5分钟,访问http://你的服务器IP:3000看到登录界面说明安装成功。
Step 2:接入大模型(5分钟)
DB-GPT支持所有主流大模型,推荐用 DeepSeek-R1(性价比最高)。
配置项 | 填写内容 |
模型类型 | OpenAI兼容接口 |
API地址 | https://api.deepseek.com/v1 |
API Key | 你的DeepSeek API Key |
模型名称 | deepseek-reasoner(R1推理模型) |
💡 提示:没有API Key?去 platform.deepseek.com 注册,新用户送免费额度,够测试用。
Step 3:连接ERP数据库(10分钟)
这是最关键的一步。在DB-GPT后台,点击「数据源管理」→「新增数据源」,填写连接信息:
配置项 | 说明 | 示例 |
数据库类型 | 选你的ERP用的数据库 | MySQL / PostgreSQL / SQL Server |
主机地址 | 数据库服务器IP | 192.168.1.100 |
端口 | 默认端口 | MySQL: 3306 / PG: 5432 |
数据库名 | ERP的数据库名 | erp_prod |
用户名 | 建议用只读账号 | erp_readonly |
密码 | 对应密码 | ******** |
点击「测试连接」,显示「连接成功」再进行下一步。
⚠️ | 为什么要用只读账号?AI生成SQL有可能写出 DELETE 或 UPDATE 语句,用只读账号,即使AI生成了危险SQL,数据库也会拒绝执行,这是最后一道安全防线。 |
连接成功后,DB-GPT会自动读取数据库的表结构(Schema),包括所有表名、字段名、字段类型、表间关联关系。这个信息会作为「上下文」送给大模型,让AI理解你的数据库长什么样。
Step 4:开始提问,验证效果(现在就能用)
在DB-GPT的对话界面,选择你刚接入的数据源,然后直接问:
本月华南区销售额是多少?
AI会自动:
• 理解你的问题
• 生成对应的SQL语句(你可以在界面上看到生成的SQL)
• 执行SQL
• 把查询结果用自然语言回答你
示例对话
👤 你:
本月华南区销售额是多少? |
🤖 AI:
本月(2026年5月)华南区总销售额为 ¥8,437,200元。
(生成的SQL:SELECT SUM(amount) FROM orders WHERE region='华南' AND create_time >= '2026-05-01'...) |
👤 你:
哪个车间本月产能达成率最低? |
🤖 AI:
本月产能达成率最低的是装配车间B,达成率 87.3%,主要原因为设备停机时长超出计划值。 |
Step 5:优化AI的准确率(重要!)
Text2SQL的准确率不是100%,有几个方法可以大幅提升:
方法1:给AI补充「表结构业务说明」
AI虽然能读取表结构,但不知道业务含义。比如 tbl_order_hdr 这个表名,AI不知道这是「订单头表」。
在数据源配置里,找到「Schema描述」,手动补充:
tbl_order_hdr:订单头表,存储订单主信息,关键字段:
- order_id:订单ID(主键)
- customer_id:客户ID,关联tbl_customer
- order_amount:订单金额
- region:所属区域(华南/华北/华东)
- create_time:下单时间
- salesperson:负责销售员姓名
tbl_production_plan:生产计划表
- plan_id:计划ID
- workshop:车间名称
- planned_qty:计划产量
- actual_qty:实际产量(关联产出表统计) |
补充完这个描述,AI生成的SQL准确率能从60%提升到90%以上。
方法2:准备「黄金SQL」示例(Few-shot)
在DB-GPT的「Few-shot示例」功能里,填入10~20条高质量问答对,AI会学习这些示例的模式,准确率进一步提升。
✅ 第一部分完成效果
你现在可以用自然语言问ERP数据,AI自动生成SQL并执行,返回答案。 |
但问题来了:
销售员张三问「我的区域销售额多少」,AI返回了全公司的数据——这显然不行。
下面解决动态权限管控问题,这是整篇文章的核心价值。
第二部分:权限管控——动态注入,不用提前建视图
这是本文最重要的部分,也是大多数教程不会讲的核心。
先纠正一个常见误区
❌ 错误做法
提前给每个用户建视图,比如 v_sales_zhangsan、v_sales_lisi……用户多了视图爆炸,而且视图写死了,AI的价值就没了。 |
✅ 正确做法
查询时动态注入权限条件——谁在查,就动态追加属于他的过滤条件,不提前建任何视图。 |
真实可行的3种权限管控方案
方案 | 原理 | 推荐场景 |
方案A:数据库层RLS
(推荐) | 数据库内置行级安全,用session变量传用户身份 | PostgreSQL
SQL Server 用户 |
方案B:应用层SQL重写 | AI生成SQL后、执行前,应用层自动追加WHERE | 所有数据库
都能用 |
方案C:阿里云DMS
行级管控 | 云平台内置,配置管控组和行值 | 用阿里云DMS
的用户 |
方案A:数据库层RLS(最彻底,推荐)
原理:利用PostgreSQL或SQL Server内置的RLS(Row-Level Security,行级安全)功能。查询时,数据库会自动根据当前用户的身份,只返回他有权限看的行。
✅ | 优点:权限在数据库层管控,应用层不需要改代码。即使用SQL注入绕过应用层,数据库仍然会过滤行,是最彻底的隔离方案。 |
PostgreSQL版实操:
Step 1:开启表的行级安全
-- 开启行级安全(对orders表生效)
ALTER TABLE orders ENABLE ROW LEVEL SECURITY; |
Step 2:创建权限策略(Policy)
策略的核心是一段「条件」——只有满足条件的行,当前用户才能看到。
-- 创建一个策略:用户只能看到 region 字段等于自己所属区域的行
CREATE POLICY orders_region_policy
ON orders
FOR SELECT
USING (region = current_setting('app.current_user_region')); |
💡 | current_setting('app.current_user_region') 是PostgreSQL的session变量,每次查询前设置好,数据库会自动用它来过滤行。 |
Step 3:查询前设置当前用户的session变量
-- 张三登录后,应用层先执行这条SQL,设置他的区域
SELECT set_config('app.current_user_region', '华南', false);
-- 然后执行AI生成的SQL,数据库会自动只返回华南区的数据
SELECT SUM(amount) FROM orders WHERE create_time >= '2026-05-01';
-- 返回的只有华南区的数据,张三看不到其他区域 |
Step 4:在DB-GPT里配置「查询前执行SQL」
在DB-GPT的数据源配置里,找到「连接初始化SQL」,填入:
SELECT set_config('app.current_user_region', '{当前用户的区域}', false); |
DB-GPT会在每次查询前自动执行这段SQL,把当前登录用户的区域写进session。全程自动,不需要手动干预。
SQL Server版实操:
SQL Server 2016+ 也支持RLS,语法略有不同。
Step 1:创建谓词函数(定义过滤逻辑)
-- 创建一个函数:判断当前用户能否访问某行
CREATE FUNCTION dbo.fn_orders_by_region()
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN SELECT 1 AS result
WHERE region = CAST(SESSION_CONTEXT(N'user_region') AS NVARCHAR(50)); |
Step 2:创建安全策略
CREATE SECURITY POLICY orders_region_policy
ADD FILTER PREDICATE dbo.fn_orders_by_region()
ON dbo.orders; |
Step 3:查询前设置session上下文
-- 应用层在查询前执行
EXEC sp_set_session_context N'user_region', N'华南';
-- 后续查询自动只返回华南区数据
SELECT SUM(amount) FROM orders WHERE create_time >= '2026-05-01'; |
方案B:应用层SQL重写(所有数据库通用)
原理:AI生成SQL之后、交给数据库执行之前,应用层自动分析SQL,追加WHERE条件。
示例:
AI生成的原始SQL:
SELECT SUM(amount) FROM orders WHERE create_time >= '2026-05-01'; |
应用层拦截后,自动改写成:
SELECT SUM(amount) FROM orders WHERE create_time >= '2026-05-01' AND region = '华南'; |
💡 | 优点:不依赖数据库版本,MySQL 5.7也能用。注意:这个方案依赖应用层正确实现,如果应用层有Bug,权限可能被绕过。 |
方案C:阿里云DMS行级管控(最简单,但依赖阿里云)
原理:在DMS里配置「管控组」,指定某个用户只能访问某些行值。查询时DMS自动注入过滤条件。
实操步骤:
1. 打开阿里云DMS控制台
2. 进入「安全与容灾 → 敏感数据管理 → 行级管控」
3. 创建管控组,比如「销售区域管控」
4. 添加行配置:选择 orders 表,管控字段选 region
5. 给每个用户添加「行值」,比如给张三添加行值 华南
6. 保存后,张三通过DMS查询 orders 表时,只能看到 region='华南' 的行
✅ | 全程界面配置,不需要写代码,非技术人员也能操作。缺点:绑定阿里云生态,不能私有化部署。 |
完整落地方案总结
步骤 | 做什么 | 耗时 | 难度 |
1 | 部署DB-GPT(Docker一键) | 10分钟 | ⭐⭐ |
2 | 接入大模型(填API Key) | 5分钟 | ⭐ |
3 | 连接ERP数据库(用只读账号!) | 10分钟 | ⭐ |
4 | 补充表结构业务说明 | 30分钟 | ⭐ |
5 | 配置权限管控(选方案A/B/C) | 1~2小时 | ⭐⭐⭐ |
6 | 试用 + 迭代(员工内测) | 持续 | ⭐ |
总耗时:约半天,就能让公司用上「AI直连ERP查数据 + 动态权限管控」。
成本估算
项目 | 费用 |
云服务器(2核4GB) | 约30元/月 |
DeepSeek API调用 | 约10~50元/月(按使用量) |
DB-GPT(开源) | 免费 |
总计 | 约40~80元/月 |
对比请一个数据分析专员:月薪6000元起。
常见问题
Q1:除了ERP,我还能接入哪些系统?
DB-GPT支持所有能通过JDBC/ODBC连接的数据库,包括:
l CRM系统(Salesforce、纷享销客等)
l MES生产执行系统
l WMS仓储系统
l HR系统、财务系统
l 甚至Excel、CSV文件(通过DuckDB)
一套方案打通所有数据源,AI会自动路由到正确的数据库。
Q2:AI生成的SQL出错怎么办?
两道防线:
1.DB-GPT界面会展示生成的SQL,执行前可以开启「人工审核模式」——SQL先给管理员审批,通过后再执行
2.用只读账号连接数据库,即使AI生成了危险的 DELETE/UPDATE,数据库也会拒绝执行
熟练后可以关闭审核,让AI直接执行。
Q3:AI生成的SQL出错怎么办?
DB-GPT界面上会展示生成的SQL,执行前可以开启「人工审核模式」:生成的SQL先给管理员审批,通过后再执行。熟练后可以关闭审核。
Q4:我们的ERP数据库是SQL Server 2008,不支持RLS怎么办?
用方案B(应用层SQL重写),不依赖数据库版本。或者升级数据库(推荐,2008已经停止支持了)。
Q5:多个ERP系统怎么办?
DB-GPT支持接入多个数据源,可以为每个ERP系统创建一个数据源,AI会自动路由到正确的数据库。
Q6:中小企业有必要上这个吗?
如果公司有以下特征,建议上:
• 老板经常要数据,每次都要等人统计(20分钟以上)
• 员工人数50人以上,数据查询需求频繁
• 已经有ERP系统,但查数据体验很差
• 有多个区域/多个销售,需要数据权限隔离
你能立刻行动的第一步
1 | 今天:梳理你们公司「最常被问到的10个数据问题」,比如「本月产能达成率」「库存预警」「供应商来料合格率」等 |
2 | 明天:去DeepSeek官网注册,拿到API Key(5分钟) |
3 | 本周:找一台闲置电脑或云服务器,按本文步骤把DB-GPT跑起来,接测试数据库先试 |
4 | 下周:试用没问题后,接入正式ERP的只读账号,邀请3~5个员工内测,收集反馈后迭代 |
阅读原文:https://mp.weixin.qq.com/s/x7tiEA6r02Lixq05NDQwVw
该文章在 2026/5/29 18:29:41 编辑过






 400 186 1886
400 186 1886